
1. 문제 상황
상품 검색 화면에서 사용자가 여러 조건(카테고리, 색상, 시즌, 가격대 등)을 선택해 검색할 때, 전체 데이터를 한 번에 가져오는 것은 불가능합니다.
대량 데이터를 한 번에 조회하면 성능 저하와 불필요한 네트워크 비용이 발생하기 때문입니다.
따라서 페이징 처리가 필수였습니다.
이 프로젝트에서는 Spring Data JPA와 QueryDSL을 결합해, 표준적이고 효율적인 페이징 패턴을 구현했습니다.
2. 기술 선택 배경
Spring Data JPA는 Pageable과 Page 인터페이스를 제공해 페이징을 간단하게 구현할 수 있습니다.
하지만, 복잡한 동적 조건이 포함된 쿼리를 작성할 때는 QueryDSL을 사용해야 가독성과 유지보수성이 높아집니다.
따라서,
- Spring Data JPA → 페이징 요청/응답 표준화
- QueryDSL → 동적 조건과 페이징 로직을 깔끔하게 결합
이 조합을 선택했습니다.
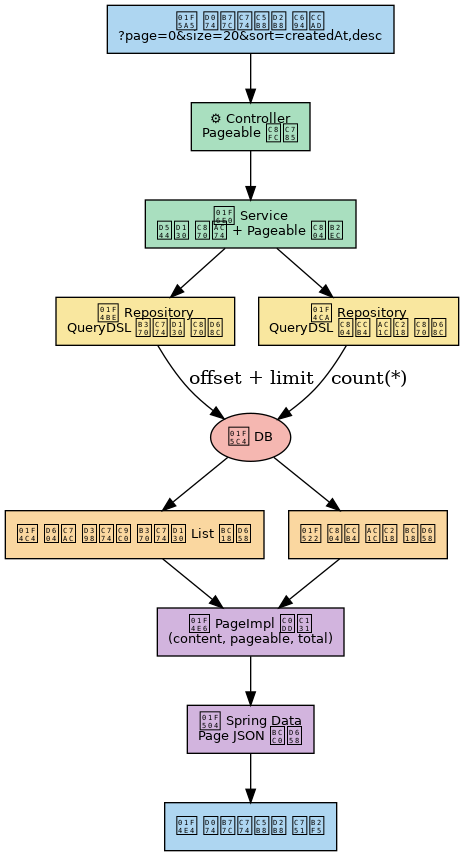
3. 구현 방식 — 4단계 페이징 프로세스
1) 페이징 정보 요청 (Pageable)
컨트롤러는 다음과 같이 Pageable 객체를 파라미터로 받습니다.
public Page<String> filterProductCodes(..., Pageable pageable)- 클라이언트는 /api/products/filter?page=0&size=20&sort=createdAt,desc 형식으로 요청
- Spring이 이를 자동으로 PageRequest 객체로 변환해 컨트롤러에 주입
- 이 객체에는 페이지 번호, 페이지 크기, 정렬 정보가 포함
2) 실제 데이터 조회
QueryDSL 쿼리에서 offset과 limit을 적용해 필요한 데이터만 조회합니다.
List<String> results = queryFactory
.select(product.productCode)
.from(product)
// ... join, where ...
.orderBy(product.createdAt.desc())
.offset(pageable.getOffset()) // 시작 위치
.limit(pageable.getPageSize()) // 개수 제한
.fetch();- .offset() → 가져올 시작 위치 (page × size)
- .limit() → 가져올 데이터 개수
- DB가 전체가 아닌 필요한 범위만 조회 → 성능 최적화
3) 전체 데이터 개수 조회
UI에서 “총 N개, M페이지” 같은 정보를 표시하려면 전체 개수를 알아야 합니다.
Long total = queryFactory
.select(product.countDistinct())
.from(product)
// ... 동일한 where 조건 ...
.fetchOne();
- 동일한 필터 조건(BooleanBuilder)을 사용하되 count()만 조회
- 대량 데이터를 불러오지 않고 개수만 계산
4) 페이징 결과 조합
PageImpl 객체로 결과와 페이징 정보를 묶어 반환합니다.
return new PageImpl<>(results, pageable, total == null ? 0 : total);
- results → 현재 페이지 데이터
- pageable → 요청된 페이징 정보
- total → 전체 데이터 개수
Spring이 이를 JSON으로 변환하면 다음과 같은 정보가 포함됩니다:
{
"content": [...],
"totalElements": 195,
"totalPages": 10,
"number": 2,
"size": 20
}4. 효과 — 효율성과 표준성
이 방식의 장점은 다음과 같습니다.
- 효율성: DB에서 필요한 데이터만 조회하여 불필요한 리소스 사용 방지
- 표준성: Spring Data JPA의 Page 표준을 따라 API 응답 구조 통일
- 유지보수성: QueryDSL의 동적 조건 조립과 페이징 로직 결합이 깔끔
- 확장성: 정렬, 필터 조건 추가 시 구조 변경 최소화
5. 결론
Spring Data JPA의 페이징 기능과 QueryDSL의 동적 쿼리 조합은
대량 데이터를 다루는 실무 환경에서 안정적이고 검증된 패턴입니다.
이 방식은 데이터 양이 많을수록 성능 이점을 발휘하며, 향후 새로운 조건이 추가되어도 쉽게 확장할 수 있습니다.
6. 핵심 코드 예시
List<String> results = queryFactory
.select(product.productCode)
.from(product)
.join(categoryList).on(product.productCode.eq(categoryList.productCode))
.where(builder)
.orderBy(product.createdAt.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
Long total = queryFactory
.select(product.countDistinct())
.from(product)
.join(categoryList).on(product.productCode.eq(categoryList.productCode))
.where(builder)
.fetchOne();
return new PageImpl<>(results, pageable, total == null ? 0 : total);
[추가] 페이징 처리 흐름 다이어그램
'공부방' 카테고리의 다른 글
| MongoDB 복합 인덱스(Compound Index) 조회 성능 테스트 (0) | 2025.09.18 |
|---|---|
| RESTful API 설계 및 구현 (0) | 2025.08.20 |
| 복잡한 동적 상품 필터링, 왜 QueryDSL을 선택했나? (2) | 2025.08.13 |
| 인덱스의 중요성, 성능 테스트로 증명하기 (2) | 2025.08.13 |
| CQRS 패턴의 진정한 가치: 부하 테스트로 증명하기 (2) | 2025.08.12 |