
VectorDB란?
VectorDB는 데이터(텍스트, 이미지, 오디오 등)를 다차원 벡터(Vector, 숫자 배열) 형태로 변환하여 저장하고, 벡터 간의 거리(유사도)를 기반으로 데이터를 검색하는 데이터베이스입니다.
- 핵심 원리: 데이터를 '임베딩(Embedding)'이라는 과정을 통해 벡터 공간상의 좌표로 변환합니다. 의미가 비슷한 데이터끼리는 공간상에서 가깝게 위치하게 됩니다.
- 기존 DB와의 차이:
- RDBMS/NoSQL: 정확한 키워드 매칭(WHERE title = 'apple')이나 패턴 매칭(LIKE)에 최적화.
- VectorDB: 의미적 유사성(Semantic Similarity) 매칭에 최적화. (예: '사과'를 검색하면 'Apple'이나 '맛있는 과일'도 찾음)

참고: 위 이미지는 단어들이 벡터 공간에서 어떻게 위치하는지 보여주는 예시입니다. 'King'과 'Queen'이 가깝고, 'Apple'과 'Orange'가 가까운 것을 볼 수 있습니다.
왜 필요한가?
최근 AI와 LLM(거대언어모델)의 부상으로 VectorDB는 "AI의 장기 기억장치"로서 필수적인 요소가 되었습니다.
- 시맨틱 검색 (Semantic Search):
- 단순 키워드 일치가 아닌, "문맥"과 "의미"를 파악해야 합니다. 사용자가 "배고플 때 먹기 좋은 거"라고 검색했을 때, '음식', '맛집'이라는 키워드가 없어도 추천해 줄 수 있어야 합니다.
- 비정형 데이터 처리:
- 이미지, 음성, 비디오 등은 기존 DB 쿼리로 검색하기 어렵습니다. 이를 벡터로 변환하면 "이 사진과 비슷한 분위기의 사진"을 수학적으로 계산하여 찾을 수 있습니다.
- LLM의 한계 보완 (RAG):
- ChatGPT 같은 모델은 학습하지 않은 최신 정보나 회사 내부 데이터는 모릅니다. VectorDB에 내부 문서를 저장해두고, 질문과 관련된 문서를 찾아 AI에게 참고하라고 넘겨줌으로써 정확한 답변을 생성하게 합니다.
작동 원리
1. 작동 과정
- 임베딩 (Vectorization): AI 모델(예: OpenAI text-embedding-3)을 사용해 데이터를 벡터(예: [0.1, -0.5, 0.8, ...])로 변환합니다.
- 인덱싱: 빠른 검색을 위해 벡터들을 효율적으로 정렬(HNSW 알고리즘 등 사용)하여 저장합니다.
- 검색 (Similarity Search): 사용자의 질문을 벡터로 변환한 뒤, 저장된 벡터 중 가장 거리가 가까운(유사한) 데이터를 찾습니다.
2. 유사도 계산 수식 (거리 측정)
주로 코사인 유사도(Cosine Similarity)를 사용합니다. 두 벡터 A와 B 사이의 각도를 측정합니다.
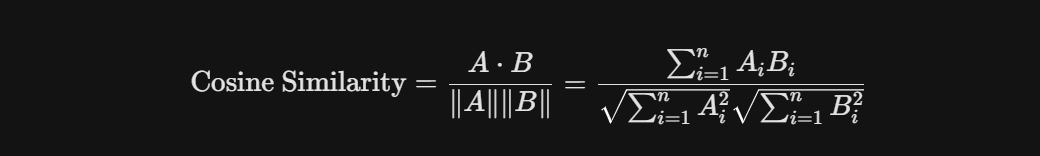
3. 대표적인 VectorDB 종류
|
분류
|
제품명
|
특징
|
|
전용(Native)
|
Pinecone
|
완전 관리형(SaaS), 사용이 쉽고 성능이 강력함.
|
|
전용(Native)
|
Milvus |
대규모 데이터 처리에 강한 오픈소스 VectorDB.
|
|
전용(Native)
|
Chroma
|
AI 개발 시 로컬 환경에서 가볍게 쓰기 좋음 (오픈소스).
|
|
확장형
|
pgvector
|
PostgreSQL의 확장 플러그인. 기존 RDBMS 스택을 그대로 활용 가능하여 백엔드 개발자에게 인기.
|
|
검색엔진
|
Elasticsearch
|
기존 검색 엔진에 벡터 검색 기능이 추가됨.
|
연관 개념
- Embeddings (임베딩): 데이터를 벡터 숫자 배열로 바꾸는 기술 그 자체.
- RAG (Retrieval-Augmented Generation, 검색 증강 생성): VectorDB에서 관련 지식을 찾아와(Retrieval) LLM이 답변하도록(Generation) 하는 아키텍처.
- ANN (Approximate Nearest Neighbor): 수억 개의 벡터 중 '정확히 제일 가까운 것'을 찾으려면 너무 느리므로, '적당히 아주 가까운 것'을 아주 빠르게 찾는 알고리즘.

한계점 (Trade-offs)
- 정확도 vs 속도: ANN 알고리즘 특성상 속도를 위해 약간의 정확도를 희생할 수 있습니다.
- 비용: 고차원 벡터 인덱싱은 메모리(RAM)를 많이 사용하며, 임베딩 API 호출 비용도 발생합니다.
- 최신성 유지: 데이터가 변경되면 임베딩을 다시 생성하고 인덱스를 업데이트해야 하므로, 실시간 데이터 동기화 파이프라인 구축이 까다로울 수 있습니다.
VectorDB를 활용한 RAG 아키텍처
RAG 아키텍처는 크게 데이터 적재(Ingestion) 파이프라인과 검색 및 생성(Retrieval & Generation) 파이프라인 두 가지 흐름으로 나뉩니다.
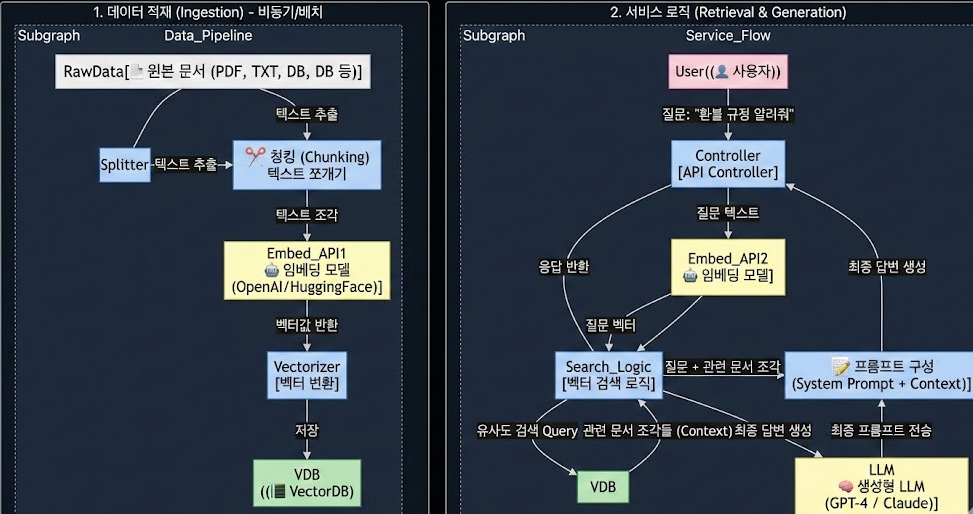
1. 데이터 적재 파이프라인 (Ingestion Flow)
사용자가 질문하기 전에 미리 지식 베이스를 구축하는 단계입니다. 보통 배치(Batch)나 관리자 기능으로 구현합니다.
- Chunking (청킹): 원본 문서를 LLM이 처리하기 좋은 크기(예: 500~1000 토큰)로 자릅니다.
- Tip: 문맥이 잘리지 않도록 문단 단위로 자르거나, 앞뒤 내용을 조금씩 겹치게(Overlap) 자르는 것이 노하우입니다.
- Embedding (임베딩): 텍스트 조각을 API에 보내 벡터로 변환합니다.
- Upsert (저장): VectorDB에 [벡터값, 원본 텍스트, 메타데이터(출처 등)]를 함께 저장합니다.
2. 서비스 로직 파이프라인 (Retrieval & Generation Flow)
실제 사용자가 채팅창에 질문을 입력했을 때 일어나는 실시간 프로세스입니다.
- Step 1: 질문 벡터화
- 사용자의 질문(Query)도 DB에 저장된 문서와 비교할 수 있도록 똑같은 임베딩 모델을 사용해 벡터로 변환합니다.
- Step 2: 유사도 검색 (Retrieval)
- 질문 벡터를 VectorDB에 보내 "가장 거리가 가까운 상위 N개의 문서 조각(Chunk)"을 가져옵니다.
- SQL 예시: SELECT * FROM items ORDER BY embedding <=> query_vector LIMIT 5; (pgvector 문법)
- Step 3: 프롬프트 엔지니어링 (Augmentation)
- 검색된 문서 조각들을 모아 LLM에게 보낼 프롬프트를 코드로 구성합니다.
- 프롬프트 예시: "너는 친절한 상담원이야. 아래 [참고 정보]를 바탕으로 사용자의 질문에 답해줘. 정보가 없으면 모른다고 해.
[참고 정보]: {검색된_문서_내용}
질문: {사용자_질문}"
- Step 4: 답변 생성 (Generation)
- 완성된 프롬프트를 LLM(GPT 등)에 보내 최종 자연어 답변을 받습니다.